Double Your Profit With These 5 Recommendations on Deepseek
페이지 정보
작성자 Lela 댓글 0건 조회 0회 작성일 25-03-23 12:40본문
 For Budget Constraints: If you're limited by funds, concentrate on Deepseek GGML/GGUF fashions that fit within the sytem RAM. RAM needed to load the model initially. These large language fashions must load completely into RAM or VRAM each time they generate a brand new token (piece of textual content). To achieve load balancing among totally different consultants within the MoE part, we need to make sure that every GPU processes roughly the same number of tokens. First, for the GPTQ version, you may need a good GPU with at least 6GB VRAM. For Best Performance: Go for a machine with a high-end GPU (like NVIDIA's latest RTX 3090 or RTX 4090) or twin GPU setup to accommodate the biggest models (65B and 70B). A system with adequate RAM (minimum sixteen GB, however 64 GB finest) could be optimum. For comparability, high-end GPUs like the Nvidia RTX 3090 boast almost 930 GBps of bandwidth for their VRAM. The H800 is a much less optimum model of Nvidia hardware that was designed to cross the requirements set by the U.S. For recommendations on the most effective pc hardware configurations to handle Deepseek fashions smoothly, check out this guide: Best Computer for Running LLaMA and LLama-2 Models.
For Budget Constraints: If you're limited by funds, concentrate on Deepseek GGML/GGUF fashions that fit within the sytem RAM. RAM needed to load the model initially. These large language fashions must load completely into RAM or VRAM each time they generate a brand new token (piece of textual content). To achieve load balancing among totally different consultants within the MoE part, we need to make sure that every GPU processes roughly the same number of tokens. First, for the GPTQ version, you may need a good GPU with at least 6GB VRAM. For Best Performance: Go for a machine with a high-end GPU (like NVIDIA's latest RTX 3090 or RTX 4090) or twin GPU setup to accommodate the biggest models (65B and 70B). A system with adequate RAM (minimum sixteen GB, however 64 GB finest) could be optimum. For comparability, high-end GPUs like the Nvidia RTX 3090 boast almost 930 GBps of bandwidth for their VRAM. The H800 is a much less optimum model of Nvidia hardware that was designed to cross the requirements set by the U.S. For recommendations on the most effective pc hardware configurations to handle Deepseek fashions smoothly, check out this guide: Best Computer for Running LLaMA and LLama-2 Models.
 Popular interfaces for working an LLM domestically on one’s personal laptop, like Ollama, already help DeepSeek R1. For detailed and up-to-date pricing information, it’s advisable to seek the advice of DeepSeek’s official documentation or contact their support group. Your browser doesn't assist the video tag. Please allow JavaScript in your browser to complete this type. You'll need around four gigs free to run that one smoothly. DeepSeek is free (for now). The model will routinely load, and is now ready to be used! Remember, these are recommendations, and the precise efficiency will rely upon a number of components, including the precise task, mannequin implementation, and other system processes. User Interface: DeepSeek supplies user-friendly interfaces (e.g., dashboards, command-line tools) for customers to work together with the system. A serious safety breach has been discovered at Chinese AI startup DeepSeek, exposing delicate consumer data and internal system data through an unsecured database. DeepSeek also emphasizes ease of integration, with compatibility with the OpenAI API, guaranteeing a seamless person expertise. It makes software program growth really feel a lot lighter as an experience. In at present's fast-paced growth landscape, having a dependable and environment friendly copilot by your facet can be a game-changer. Having CPU instruction sets like AVX, AVX2, AVX-512 can further enhance efficiency if available.
Popular interfaces for working an LLM domestically on one’s personal laptop, like Ollama, already help DeepSeek R1. For detailed and up-to-date pricing information, it’s advisable to seek the advice of DeepSeek’s official documentation or contact their support group. Your browser doesn't assist the video tag. Please allow JavaScript in your browser to complete this type. You'll need around four gigs free to run that one smoothly. DeepSeek is free (for now). The model will routinely load, and is now ready to be used! Remember, these are recommendations, and the precise efficiency will rely upon a number of components, including the precise task, mannequin implementation, and other system processes. User Interface: DeepSeek supplies user-friendly interfaces (e.g., dashboards, command-line tools) for customers to work together with the system. A serious safety breach has been discovered at Chinese AI startup DeepSeek, exposing delicate consumer data and internal system data through an unsecured database. DeepSeek also emphasizes ease of integration, with compatibility with the OpenAI API, guaranteeing a seamless person expertise. It makes software program growth really feel a lot lighter as an experience. In at present's fast-paced growth landscape, having a dependable and environment friendly copilot by your facet can be a game-changer. Having CPU instruction sets like AVX, AVX2, AVX-512 can further enhance efficiency if available.
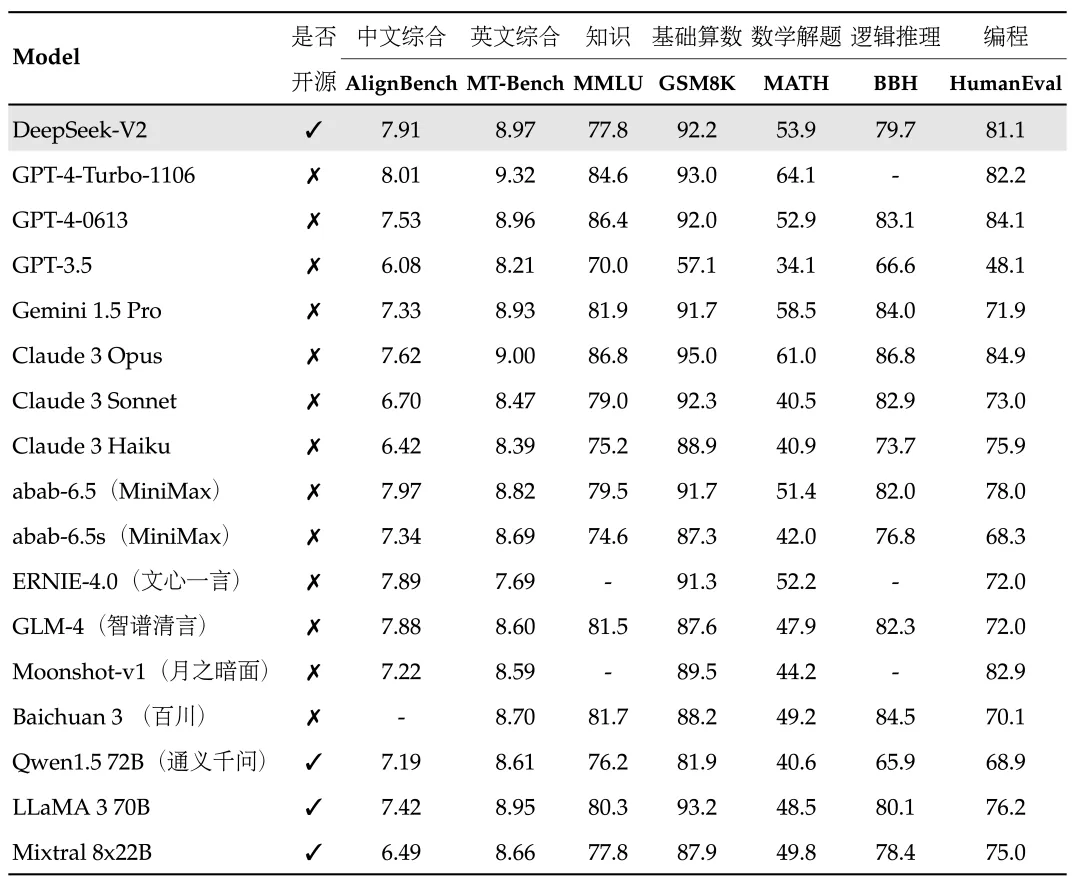
Featuring the DeepSeek-V2 and DeepSeek-Coder-V2 fashions, it boasts 236 billion parameters, providing high-tier efficiency on main AI leaderboards. Whether for analysis, growth, or practical application, DeepSeek provides unparalleled AI efficiency and value. Twilio SendGrid provides dependable supply, scalability & real-time analytics along with versatile API's. The flexibleness to run a NIM microservice on your safe infrastructure additionally supplies full management over your proprietary information. Tsarynny instructed ABC that the DeepSeek application is able to sending user knowledge to "CMPassport.com, the web registry for China Mobile, a telecommunications company owned and operated by the Chinese government". DeepSeek distinguishes itself with its strong and versatile options, catering to a variety of person needs. As 7B and 14B variants unlock, you should see DeepSeek R1’s Azure model enhance, though if you want to test it out you might want to do so sooner somewhat than later. See the installation instructions and utilization documentation for extra details. To achieve a better inference velocity, say sixteen tokens per second, you would want extra bandwidth.
When running DeepSeek v3 AI fashions, you gotta pay attention to how RAM bandwidth and mdodel measurement influence inference speed. Suppose your have Ryzen 5 5600X processor and DDR4-3200 RAM with theoretical max bandwidth of 50 GBps. The DDR5-6400 RAM can provide up to one hundred GB/s. But for the GGML / GGUF format, it's more about having sufficient RAM. More parameters sometimes imply extra computing effort. I’m getting so way more work done, but in much less time. An Intel Core i7 from 8th gen onward or AMD Ryzen 5 from third gen onward will work properly. Start a new project or work with an present code base. Start your response with hex rgb colour code. Aider permits you to pair program with LLMs, to edit code in your local git repository. Explore all versions of the model, their file codecs like GGML, GPTQ, and HF, and perceive the hardware requirements for local inference.
When you liked this post in addition to you desire to get guidance regarding Deepseek Ai Online Chat i implore you to stop by our own webpage.
- 이전글Why Deepseek Chatgpt Succeeds 25.03.23
- 다음글The Anatomy Of Deepseek Chatgpt 25.03.23
